Structured to Scale: The Architecture Call Most Teams Get Wrong
In one last post, I argued that technical knowledge lives in concepts, not syntax—that a skilled engineer picks up a new language in weeks because the underlying patterns transfer. The same principle applies one level up: the patterns you apply are only as good as the moment you choose to apply them. The choice that matters most at the start of any new system is the very first one—how you structure the application before writing a single feature.
When I started ClickNBack, microservices were the obvious answer. They’re what serious distributed systems look like, right? The patterns are well-documented, the tooling is mature, the case studies are everywhere. And yet I built a modular monolith—deliberately, with a written record of why. Here’s the reasoning.
Why Microservices at Day Zero Is a Trap
The appeal of microservices is real: independent deployments, isolated failure domains, the ability to scale components individually. For engineers who’ve inherited a monolith that devolved into an unmaintainable tangle, that story is viscerally compelling.
But in a financial domain (most domains actually), microservices from day one introduce problems that are far harder than the coupling you’re trying to avoid. Wallet credits and purchase confirmations require ACID guarantees. When those operations span two independent services, a database transaction becomes a saga—a coordinated sequence of compensating actions designed to handle partial failures, duplicate signals, and network timeouts. Sagas have well-known solutions. Those solutions also require weeks of implementation before you’ve shipped a single cashback calculation.
The trigger for microservices should be real, not assumed: a domain with scaling needs that diverge from the rest of the system, or team ownership boundaries that make shared deployments a coordination burden. Neither condition existed at ClickNBack’s inception. Choosing microservices anyway would have meant optimizing for a problem I didn’t have—and creating new ones I didn’t need.
Why the Traditional Monolith Isn’t the Answer Either
The obvious alternative is the traditional layered monolith: all models together, all services together, all routes together. It looks disciplined until the codebase grows, and then you discover that understanding any single feature requires reading across every technical layer simultaneously.
This structure fights you at the worst possible time—when you’re adding a new feature and realize you’re touching files that were last modified in a completely different context. Tests become integration-heavy because nothing is genuinely isolated. Dependencies are implicit, not injected. The codebase resists the property you need most: the ability to change one thing without unexpectedly affecting something else.
What a Modular Monolith Actually Looks Like
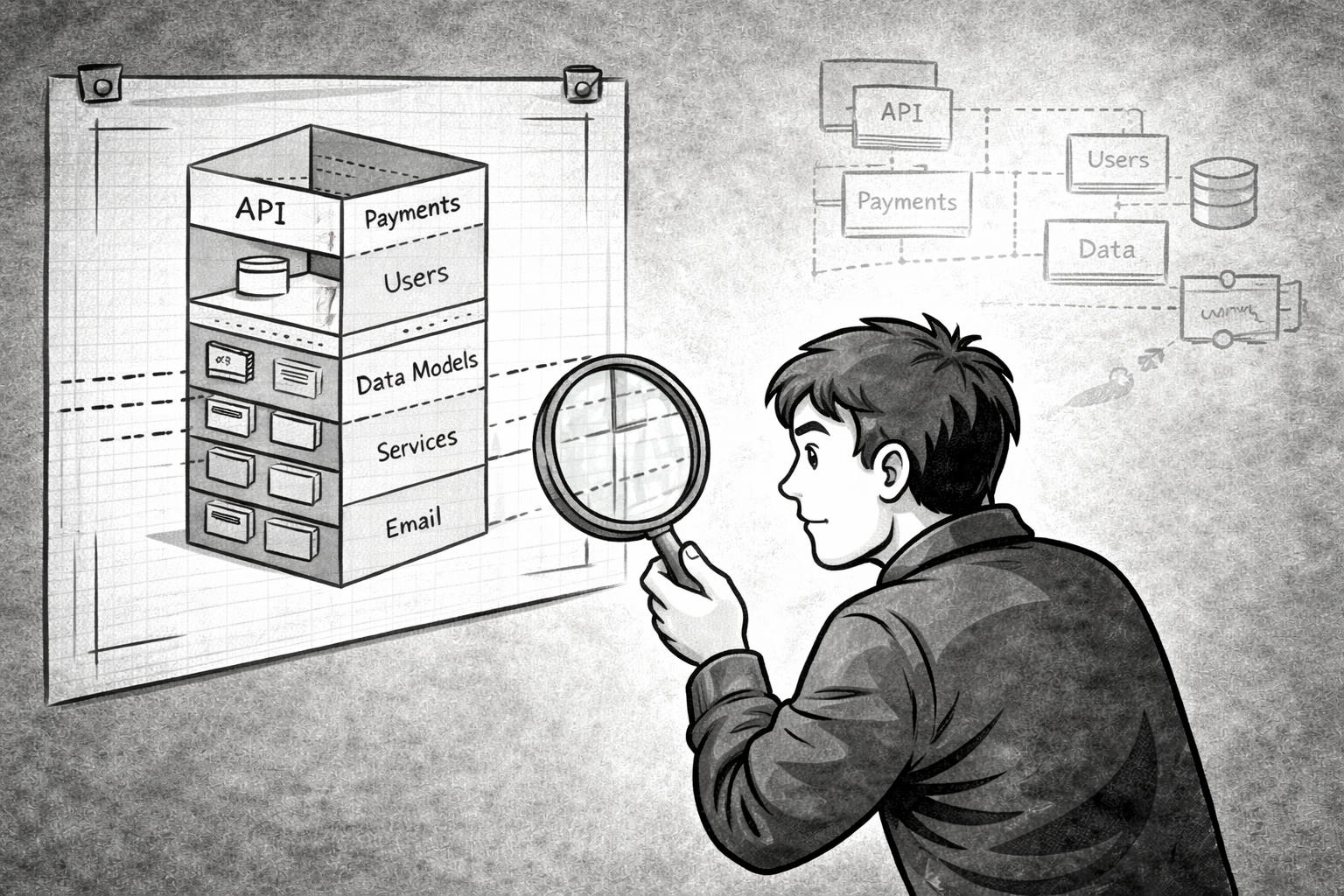
A modular monolith organizes a single deployable process by business domain rather than technical function. In ClickNBack, every domain—users, merchants, purchases, cashback, wallets—is a self-contained vertical. Its models, repositories, services, and domain exceptions all live together. A developer can read app/purchases/ and understand all purchase behavior without consulting another module.
The rule that creates this property is explicit: no module imports another module’s internal implementation. Domains communicate through defined interfaces only—never by reaching directly into each other’s repositories. Cross-module calls don’t tunnel into shared data access; they go through boundaries that can be swapped for network calls when the time comes. The full structure is in the public repository.
The result is a codebase where each domain is independently comprehensible and independently testable without a database—because dependencies are injected, not assumed.
The Extraction Trigger Is Explicit, Not Open-Ended
The crucial nuance is that a modular monolith doesn’t choose “never extract.” It chooses “extract when the trigger is real.” ADR-001 names the trigger precisely: a domain needs independent deployment, or team ownership has diverged to the point where shared deployments create coordination overhead. When that moment arrives, the service interface is already defined. Replacing an in-process call with an HTTP call becomes a localized change in one file; the rest of the domain logic never knows the difference.
That is not a compromise. It’s the deliberate deferral of complexity until the complexity is justified—which is one of the clearest expressions of senior engineering judgment I know.